A Swiss Knife python package for fast Data Science and Machine Learning
Have you ever dreamed of having some snippets of code to read any type of files on disk, display many graphs at same time, create and auto-size save histogram in one liner in python,…. ?
Of course, there are pandas, matplotlib, seaborn, but don’t you write over and over the same code, or search into Stack-Overflow the same snippets.
This is what utilmy does :
A large collection of One-Liner functions to increase daily productivity for daily Machine Learning and Data Science and fast prototpying.
Do people use it ?
Over 1 million downloads, 100k download per month

https://pepy.tech/project/utilmy
Some example :
1) Save / Reload your entire python session(with all variable names).
Ideal if you need to re-start your laptop
pip install — upgrade utilmy
#### Save current python session on disk.
from utilmy import Session
sess = Session("ztmp/session")mydf = pd.DataFrame([1], columns=['a'] )
sess.save('mysess', globals())
sess.show()del mydf
sess.load('mysess')
print(mydf)
2) Read and concatenate files from disk in parallel way into Pandas dataframe.
from utilmy import pd_read_file
df = pd_read_file([“path1/data*.parquet”, ‘path2/datab_*.csv’], n_pool=4)
Install is : pip install utilmy
Plot interactive Graph in ONE line of code :

from utilmy.viz import vizhtml as vi

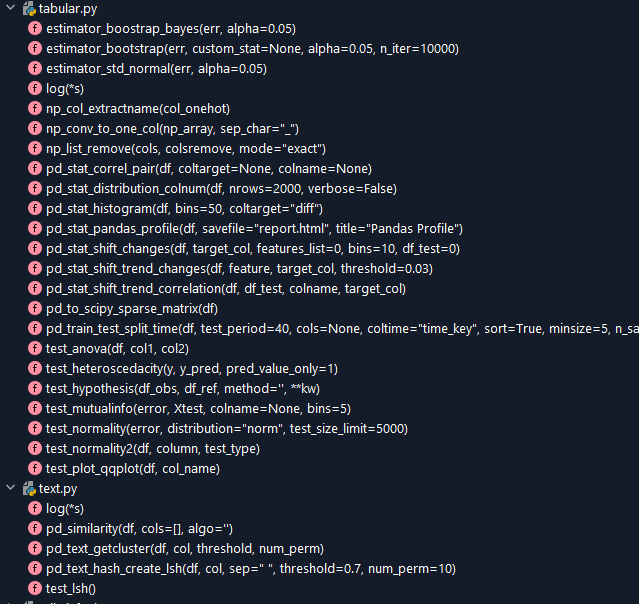
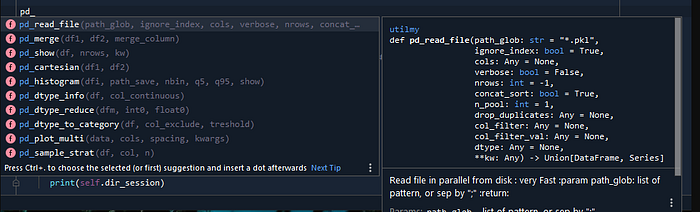
List of function available (in in Pycharm):
from utilmy import XXXXX

from utilmy.tabular import XXXX
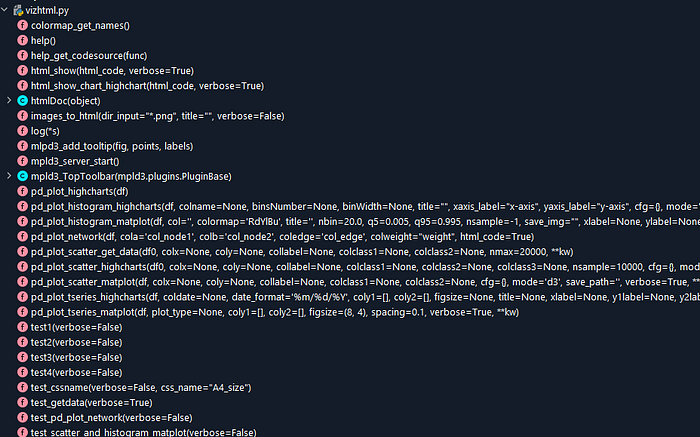
Other possibilities:
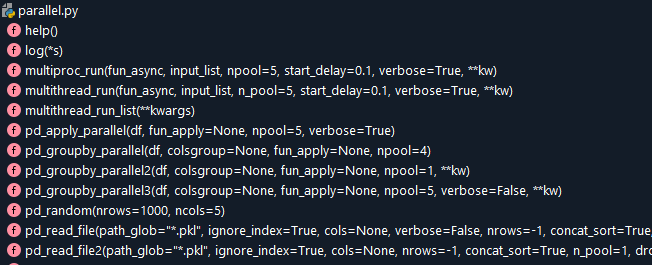
Reading any File to Pandas Dataframe
from utilmy import pd_read_filedf = pd_read_file([“path1/data*.parquet”, ‘path2/datab_*.csv’], n_pool=4)The pd_read_file function lets you read and concatenate files from the local disk. It applies parallelization to improve speed and efficiency.
One function name → reads many file type → into dataframe
Saving a Dataframe to File
from utilmy import
pd_to_file(df, "data.csv", show=1)The pd_to_file() function lets us easily save a pandas dataframe to the local disk. It automatically detects the file format.
Plotting Multiple Variables
from utilmy import pd_plot_multi
pd_plot_multi(df_weather, cols=['T (degC)', 'Tpot (K)'] )
The pd_plot_multi() function lets us quickly plot multiple variables from a pandas dataframe. We only have to specify the dataframe, as well as a list with the columns that we want to be plotted. After doing that, a matplotlib graph is displayed.
Applying Stratified Sampling to a Dataframe
from utilmy import pd_sample_strat
pd_sample_strat(df1, col, n)The pd_sample_strat() function lets us apply stratified sampling on a specific dataframe column. For every unique value of the specified column n random samples will be selected, while the rest are going to be dropped.
Binning Numeric Values
from utilmy import pd_col_bins
pd_col_bins(df1, col, nbins=10)Binning is the process where continuous numeric values are grouped in intervals known as bins. This can be easily accomplished with the pd_col_bins function. You simply have to specify a pandas dataframe, the numeric column you want to apply binning to and the number of bins.
Converting a Date to Unix Timestamp
from utilmy import to_timeunix
to_timeunix("2020-05-15")Getting the Unix timestamp of a date can be useful in many cases. This can be accomplished easily with the to_timeunix() function. You simply pass the date as a string, and the Unix timestamp is returned.
Getting OS Memory Information
from utilmy import os_memory
os_memory()Knowing how much RAM memory is available is useful in many occasions. The os_memory() prints the total RAM of the system, as well as the amount that is free and used at that time.
Getting the Number of CPU Cores
from utilmy import os_cpu
os_cpu()The os_cpu() function prints the number of CPU cores available. This function can be useful in case you are working on a remote machine and don’t know how many cores it has. Furthermore, you can use it to define the number of cores that should be utilized in functions that support parallel processing.
Getting the Working Directory in Unix format
from utilmy import os_getcwd
os_getcwd()The os_getcwd() function returns the current working directory of the OS,
in correct Unix format “/” (windows is converted to Unix).
Getting the Intersection of Two Lists
from utilmy import np_list_intersection
np_list_intersection([1, 2, 3, 4], [3, 4, 5, 6])The intersection of two lists contains the elements that are contained in both of them. We can do that easily with the np_list_intersection() function, that takes two lists as parameters. In this example, the returned list will be [3, 4] as those are the two common elements.
Documentation
https://pypi.org/project/utilmy/
https://groups.google.com/g/utilmy
Over 1 million downloads, 100k download per month